
算法题型:单调栈
图论
图论也是一个大章节,内容很多,这里我没有完全走《代码随想录》的内容,而是夹杂着写了点灵神的题单
基础理论
图的分类:有向图,无向图,权值图
度的概念:
- 表示有多少个路径和这个节点相连
- 入/出度:分别某一个节点进入和出去的路径数量
连通性:
- 连通图:(无向图)任何一个节点可以到达所有其他的节点
- 强连通图:(有向图)任何一个节点可以到达所有其他的节点
- 连通分量:(无向子图)在分量中的任何两个顶点都可以经由该图上的边抵达另一个顶点,且没有任何一边可以连到其他子图的顶点
有点抽象,一张图来理解一下
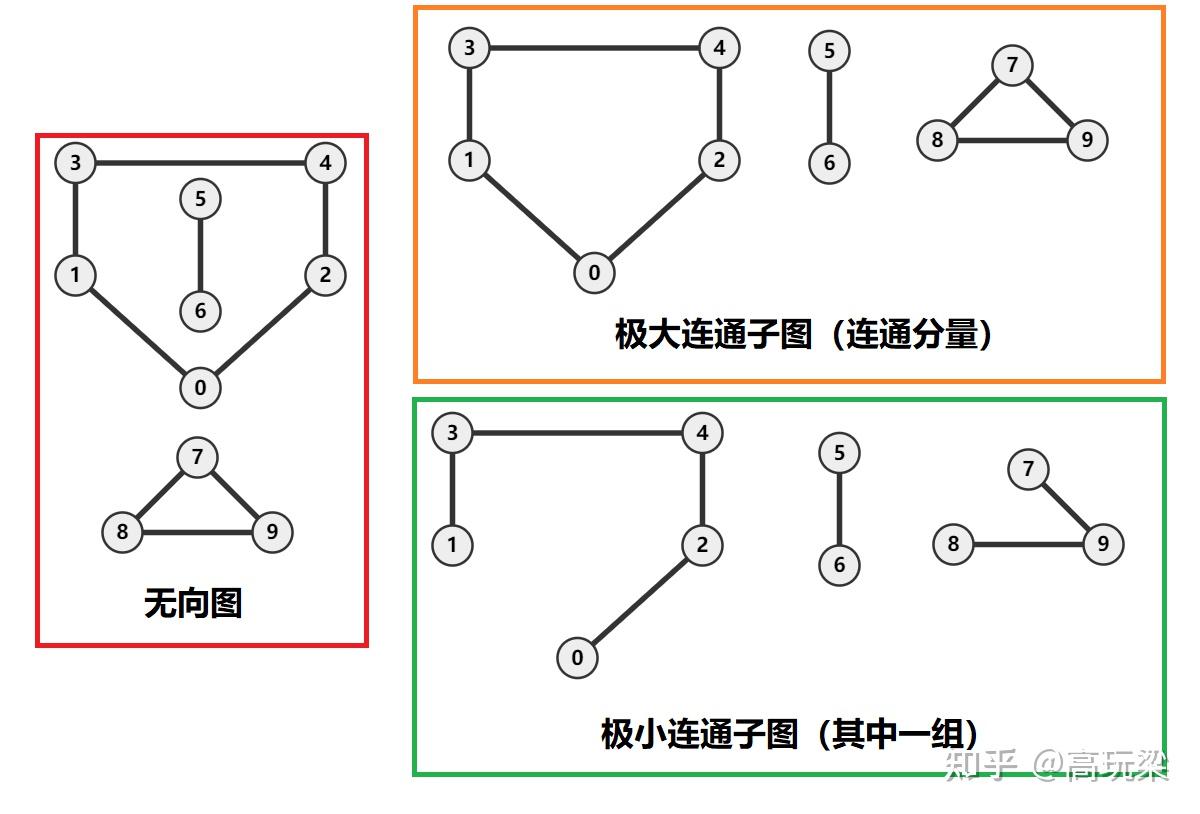
- 强连通分量:(有向图)同上
图的构造方式
- 朴素存储:把所有的边的两个节点用一个[n * 2] 的数组(也可以用
map)来存放
缺点:如果要求两个节点是否相连,必须要遍历所有的点
邻接矩阵:用一个二维矩阵存储,每一个节点代表一个坐标,坐标的值代表连通性(或者权)
缺点:非常吃内存,节点一多就极其耗费内存,不论边多少都要耗费固定值的内存
- 邻接表:数组+链表,数组代表边,链表引出所有的跟他相连的节点,以边为核心构造整个图
缺点:结构复杂,遍历和构造都相对复杂,做题能不用就别用
算法理论
深度优先搜索 DFS
DFS 一个点搜到底,到终点了(或者无路可走)再回溯
选定一个起点,一个终点
- 在找到到达终点的路径后,撤销最近一次搜索,换一条路搜
- 在某一个节点无路可走(所有的路径都已经访问过),撤销,换路
DFS 三部曲:
- 确定函数和参数(一开始可能确定不了,边写边改)
- 确定终止条件(务必明确终止条件,这是核心)
- 递归逻辑(回溯)
代码演示,这是一个完整的 ACM 模式的 DFS 代码,第一行输入 节点和边的数量,后续输入节点,这里用的是邻接矩阵写的
#include <iostream>
#include <vector>
using namespace std;
vector<vector<int>> ret;
int n = 0;
void dfs(vector<vector<int>>& graph, vector<int>& path) {
// 二维放返回值
if (path.back() == n) {
// 返回,存放结果
ret.push_back(path);
return;
}
int curr = path.back(); // 当前节点
for (int j = 1; j <= n; j++) {
if (graph[curr][j] == 1) {
path.push_back(j);
dfs(graph, path);
path.pop_back();
}
}
}
int main() {
int m;
cin >> n >> m;
// 构造邻接矩阵
vector<vector<int>> graph (n + 1, vector<int>(n + 1, 0));
int a ,b;
for (int i = 0; i < m; i++) {
cin >> a >> b;
graph[a][b] = 1;
}
vector<int> path;
path.push_back(1);
dfs(graph, path);
for (vector<int>& pt : ret) {
int sz = pt.size();
for (int i = 0; i < sz - 1; i++) {
cout << pt[i] << ' ';
}
cout << pt[sz - 1] << endl; // 这是正常的输出
}
if (ret.empty()) {
cout << -1 << endl; // 这是没有找到边的输出
}
}广度优先搜索 BFS
BFS 扩散方式搜索,栈和队列都可以,但是一般都用队列
把将要搜索的目标全部加入到队列中,然后取出一个节点,处理这个节点的所有邻接节点(注意不要处理来源的那个节点)
代码实现
// 假设使用邻接矩阵的方式来存放,图是一个正方格子的图
// grid 数组, visited 是访问过的节点, x y 是当前处理的节点
void bfs(grid[][], visited[][], x, y) {
queue<pair<int, int> que; // 存放 (x, y) 的坐标
que.push(pair<int, int> (x, y));
visited[x][y] = 1; // 标记已经访问过的节点
while (!que.empty()) {
// 遍历队列
auto node = que.front();
que.pop();
for (每个方向) {
nx, ny = 新坐标; // 取所有的方向的四周的节点,放进队列
if (越界 || visited[nx][ny]) continue;
que.push(节点); // 加入到队列
visited[nx][ny] = 1; // 标记已访问
}
}
}BFS 另一个重要的作用就是检查层数,可以用 for _ in range(len(q)) 来直接遍历完当前的层
对于非网格的图,我们通过记录层数 + 遍历队列的长度可以知道当前在哪一层
q = deque([id])
visited = [False] * len(friends)
visited[id] = True
curr_level = 0 # 当前等级
while q and curr_level < level:
for _ in range(len(q)): # 用循环长度控制 层数
u = q.popleft()
for v in friends[u]:
if not visited[v]:
visited[v] = True
q.append(v)
curr_level += 1并查集
将两个元素添加在同一个集合中,判断两个元素是否在同一个集合
- 添加:
fathter[a] = b, father[b] = c, father[c] = c表示a, b, c在同一个集合内 - 判断:找
a, b的根节点,发现都是c于是表示a, b都在同一个集合内
代码实现
int father[5] = {0};
void init(int n) {
// 初始化,让所有的元素指向自己,构建单独集合
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
int find(int u) {
if (u == father[u]) return u;
int f = find(father[u]);
return f;
}
bool isSame(int a, int b) {
return find(a) == find(b);
}
void join(int a, int b) {
a = find(a);
b = find(b); // 两个都化作根节点
if (a == b) return; //已经在同一个集合里面了
father[a] = b; // 让根相连接
}路径压缩
如果我们的层数很多,那么递归会非常的深,效率是很低的
因此我们可以用路径压缩,让所有的元素直接指向根节点
int find(int u) {
if (u == father[u]) return u;
father[u] = find(father[u]); // 将找到的根直接赋值给元素,跳过中间所有的路径
return father[u];
}秩优化
并查集可以用秩(树的近似高度)来进一步优化查找的速度
我们额外用一个数组 sz 来存放每一个集的大小,把更小的那个树挂在更大的树下面
a 挂到 b 下面,会让 a 第一次 find 深度 + 1(在路径压缩的情况下),秩的作用是让尽可能少的节点深度 +1
sz 的实际意义是:以 root 作为根的这棵并查集树中,当前包含的节点总数(sz 只有在下标实际上是一个根的时候才有意义)
sz[n] = {1}; // 初始所有的集合大小都是 1
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b) return; // 有秩必须提前返回,否则秩会错误累加
if (sz[a] < sz[b]) swap(a, b); // 保证 a 是大集合的根
father[b] = a;
sz[a] += sz[b]; // 更新 sz,
}带权图
当两个节点之间带上权的时候,需要在路径压缩的时候更新权重
如果权重的关系是累加
最小生成树 MST
最小生成树指的是给定一些节点,并已知他们之间的权值,求一个让所有节点互通的一个树
为什么是树呢,因为 MST 一定不会有环,这和 684. 冗余连接 构成了互补,MST 就是排除成环的边,剩下的全要
Prim 算法
Prim 算法类似于 Dijkstra 算法,适用于稠密图(也就是节点之间的链接越多越好)
- 找到非生成树中距离生成树最近的节点的距离
- 把这个节点加入到生成树
- 更新生成树路径(只需要更新最后一加入的那个节点,因为生成树不允许间接路径,只有直接路径权)
Prim 需要维护一个数组,存放的是每一个节点距离生成树的距离,最开始都是无穷
Kruskal 算法
Prim 是从 节点出发,逐渐扩展树,Kruskal 算法是从边出发的扩展,对边进行排序(Kruskal 更适合稀疏图)
- 对边排序
- 拿到最小权的那个边,如果两个节点不在同一个集合就加入,否则丢弃
- 更新已经进入的节点数
同一个集合(并查集):如果都不是已经生成的树里面,就无法扩展;如果都在树里面,就一定会产生环
拓扑排序
拓扑排序,对一个有向图找到一个合适的遍历顺序
拓扑排序就两个步骤,实际不是很复杂,实际应用中可以包含 BFS 和 DFS 两种写法,一般 BFS 就够用了(也就是 Kahn 算法)
- 找到入度为 0 的节点(没有就表示有环了)
- 把他和相关的边全删除
注意几点代码相关的优化:
- 看情况适用邻接表还是邻接矩阵(一般都是邻接表好用)
- 使用入度数组(统计节点的入度数量)而不是遍历表进行删除节点
- 使用队列而不是每一次扫一遍入度数组
- 根据邻接表直接删入度数量,入度清零就入队
题目节选
岛屿数量(孤岛计数)
实际上是一个图的遍历过程,模板题,包含 BFS 和 DFS,使用 ACM 模式
#include <iostream>
#include <vector>
#include <queue>
#include <utility>
using namespace std;
const int direct[][2] = {{0, 1}, {1, 0}, {-1, 0}, {0, -1}};
int m, n;
void dfs(vector<vector<int>>& map, int x, int y) {
// 从给定的节点输入,dfs 找到最大的范围,全部标记为已经访问
if (x < 0 || x >= m|| y < 0 || y >= n) return; // 越界退出
if (map[x][y] != 1) return;
map[x][y] = 2; // 立刻标记已经访问
for (int i = 0; i < 4; i++) {
// 标记当前的位置为已经访问过了
int nx = x + direct[i][0];
int ny = y + direct[i][1];
dfs(map, nx, ny); // 处理下个节点
}
}
void bfs(vector<vector<int>>& map, int x, int y) {
queue<pair<int, int>> que;
que.push({x, y}); // 原地构造直接放入
map[x][y] = 2;
while(!que.empty()) {
auto [cx, cy] = que.front();
que.pop();
// 放进去 4 个邻接节点
for (int i = 0; i < 4; i++) {
map[cx][cy] = 2; // 立刻标记已经访问
int nx = cx + direct[i][0];
int ny = cy + direct[i][1];
if (nx < 0 || nx >= m|| ny < 0 || ny >= n) continue; // 越界退出
if (map[nx][ny] != 1) continue;
map[nx][ny] = 2;
que.push({nx, ny});
}
}
}
int main() {
cin >> m >> n;
vector<vector<int>> map(m, vector<int>(n, 0));
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
cin >> map[i][j];
}
}
int count = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (map[i][j] == 1) {
// dfs(map, i, j);
bfs(map, i, j);
count += 1;
}
}
}
cout << count << endl;
return 0;
}冗余连接
去除一个图的一条边,让他成为一个无向无环图,也就是一棵树
解法是:遍历每一个边,并看当前即将连上的边是不是让两个 已经连接在一起的节点 重新连接了一遍
class Solution:
def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:
# 并查集, 节点 1~n
n = len(edges)
father = list(range(n + 1))
size = [1] * (n + 1)
def find(a):
if father[a] == a:
return a
father[a] = find(father[a])
return father[a]
def union(a, b):
a = find(a)
b = find(b)
if a == b:
return
if size[a] < size[b]:
a, b = b, a # a 更大集合
father[b] = a
size[a] += size[b]
for a, b in edges:
if find(a) == find(b): # 已经是一个集合了,重复路径
return [a, b]
else:
union(a, b)
评论已关闭