
BLIP2 论文笔记
BLIP2
来自论文: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
该文章需要有 CLIP 前置基础
背景
CLIP 使用双塔模型将图像和文本 embedding 到同一个空间,但是这并不意味着可以直接把 embedding 完毕的图像直接输入给 llm,因为他的主要作用是判断 “这个图像和文本是否匹配”,直接输入主要有三个问题:
- 维度不匹配,各种llm训练时候的维度和 CLIP 本身不匹配
- 分布不匹配,即使使用线性层对齐了维度,但是 CLIP 训练出来的维度和 llm训练时候 向量的语义,统计意义等内容也不是相同的,对于 llm 可能就是一些奇怪的 token
- 语义粒度不一致,CLIP 的 embedding 大致就是一个非常概览的图片描述,但是 llm 是更加详细具体的内容
因此最后看来大致有3个方法:
- 训练一个线性层对齐,效果实际不佳 (见上文)
- 把视觉信息直接转成文本描述,自然语言作为桥梁
- Q former,BLIP2 就是使用这个方法
简介
BLIP2 用一个小型 Q-Former 连接冻结的视觉模型和 LLM,从而以极低训练成本获得强大的 zero-shot1 多模态能力,其优点包括:
- 同时利用已经训练好的视觉模型和语言模型,并保持它们冻结,直接用得上基模的能力
- 由于接入了 llm ,所以具有 zero-shot 的生成能力,可以完成 VQA(问答), caption(描述), retrieval(检索)等问题
- 计算效率高,因为只用了一个 Q former,冻结了 llm 和 视觉 encoder,所以训练参数和效率都很高
- 有可扩展性,因为基模是可以更换的,但是 BLIP2 只是中间那个桥梁
BLIP 之前主要有两类工作完成多模态的桥接:
- End-to-end Vision-Language Pre-training,也就是把视觉,语言,encoder 等等全部揽入其中,模态理解充分,但是参数巨大,训练困难
- Modular Vision-Language Pre-training,就是 BLIP2 使用的桥接方案,训练快且可以利用好已经训练完毕的强大的基模
架构

Image Transformer
在论文中使用了 32 个 query,每一个query 维度是 768,每一个 query 都是模型训练时学习出来的,query 和 图像特征做 cross attention(以下简称 ca) 来获取图像中的信息。
此时图像编器的被冻结,其输出作为 attention 的 kv 数据,因此每一个 query 都能看到图像哪些 token 对自己最有用,可以说 Q former 是主动在图像中检索信息
image 的 self attention(以下简称 sa)输入来自于模型学习到的 query
论文中描述说 ca 是每隔一个插在 image transformer 里面的,意味着 q former 不是每一层都去拿到图像的信息,而是现在 query 中执行 sa 的整理,然后周期性拿图像信息,减少计算量和对图像文本的过度依赖
Text Transformer
text 的 sa 输入是 text token,在训练的过程中也就是对图像的文本描述 token
注意 text 的 sa 和 image 的是共享的同一套参数,也就是说 他们不是独立的网络,query token 和 text token 是可以进入 同一个主干,通过配置 attention mask 可以控制他们之间是否可以相互可见,从而实现任务下的规则切换
因此 Q former 的 sa 有 query-query, text-text, query-text 的交互功能,这解释为什么 它能够同时执行 Representation Learning 2和 Conditional Generation3的工作
Frozen Image Encoder
指的是和 Image Encoder 结合的工作,是第一阶段预训练,构建视觉和语言的表征学习
主要目的是为了让 Q former 学习如何抓住图文相关信息,学习 query 对齐工作,有三个内容,他们共同联合训练的(类似于有3个分支,最后联合构架一个 loss 对 模型参数更新)
- Image-Text Contrastive Learning,学习语言的整体对齐工作
- Image-grounded Text Generation,学习看图说话
- Image-Text Matching,学习图文整体对齐能力
三种方案都是对同一个 sa 执行训练的,各自的 attention mask 是不一样的
- ITC: 和 CLIP 很相似,就是图文匹配,偏向于全局的相似度匹配,所以 query 和 text 不能相互查看,否则类似于泄题了
- ITG:给定图像支持生成文本,是一种早期的 caption 学习信号,让 query 能够提取到图片中重要的关键信息,他的 mask 就是 text token 不能看到后面的 text token,这在生成式常见的 mask
- ITM:更加细致的匹配规则,比 ITC 更加强调细节,没有 mask,最后生成的一个匹配的分数,注重细节
Frozen LLM
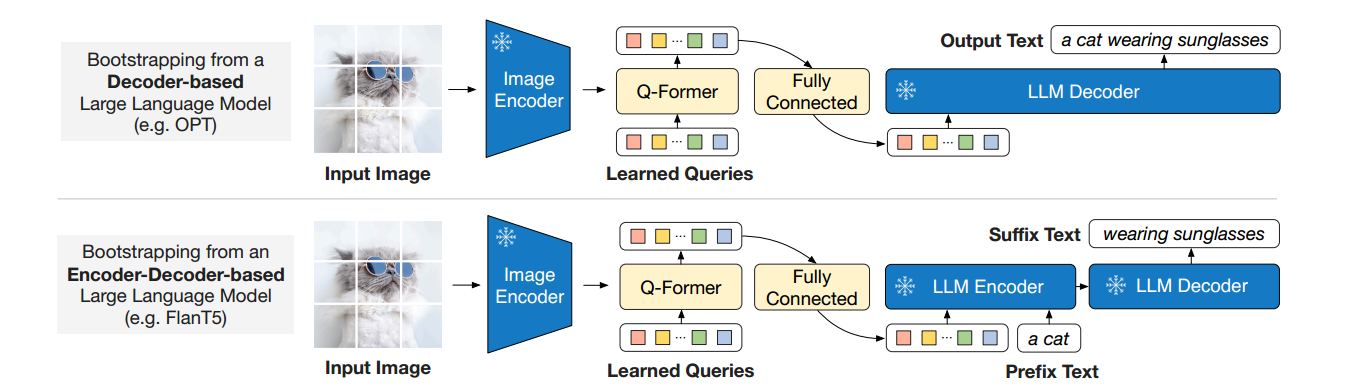
从一个冻结的大语言模型出发,启动 从视觉到语言的生成学习,也就是如何可以把 Q former 拿到的信息转成 llm 看得懂的东西,然后就可以利用 llm 已经具备的强大能力
末尾要补上一个 全连接层,把维度转化到 llm 的维度,然后接入 llm
Soft Visual Prompts
这是这篇文提出的一个概念,指的是 Q former 的输出经过投影后,以一组连向量的形式(像一个 prompt 一样放在 llm 的输入前面)告诉 llm 这张图的大致含义
但是他又不是自然语言的形式,所以是一种类 prompt
而且 Q former 的作用是提取出图像中最主要的信息,而不是所有信息,所以能够减少 llm 的上下文压力
Decoder-based LLM
论文在这一节里讨论了两类 LLM,这种类似于 GPT 的单 Decoder 形式
输入是 visual tokens + text, 输出就是文本,使用 language modeling loss 执行自回归训练,给定前一个 token 来预测下一个 token
目标是:给定一组向量,让 llm 当做有意义的前缀条件,从而生成正确的文本
Encoder-Decoder-based LLM
将文本拆成 prefix text + suffix text
encoder 输入 = visual representation + prefix text
decoder 目标 = suffix text
使用 prefix language modeling loss,给定一部分前缀条件,用来生成剩余的后缀
- Zero-shot(零样本学习,Zero-shot Learning, ZSL): 指的是模型在没有见过某个任务或类别训练样本的情况下,仍然能够完成该任务。 ↩
- Representation Learning(表示学习、表征学习):指的是让模型自动学习数据的特征表示(feature representation),而不是人工设计特征,常见的表示学习包括自监督学习、对比学习等,目标是将数据变成语义向量。 ↩
- Conditional Generation(条件生成):指的是生成模型中,生成结果依赖某个条件。例如 llm 中依赖于输入来生成文本,image caption 中针对图像生成描述等,目标是根据条件生成数据。 ↩