
Qwen-VL 技术报告笔记
Qwen-VL 系列笔记
包含 4 个文章(都在 arxiv 上)的笔记,分别是:
- Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
- Qwen2.5-VL Technical Report
- Qwen3-VL Technical Report
另外,参考了知乎笔记 多模态技术梳理:Qwen-VL系列
文章涉及内容较多,需要有:CLIP, BLIP2, LLaVA, RoPE 的前置
VLM 基础
参考一篇综述文章:MM-LLMs: Recent Advances in MultiModal Large Language Models

在 MM-LLM 中,整体架构都是以 llm 作为核心,利用好其强大的指令遵循和世界知识能力,总体而言可以分为这几个框架:
- Modality Encoder:将各种多模态的数据编码成向量,例如 ViT 或者 ResNet等,一般都是单独进行预训练的
- Input Projector:将上一个给出的向量空间,映射到 llm “看得懂” 的空间中,一般来说结构相对简单,例如 LLaVA 中的 MLP 或者 BLIP2 中的 Q-Former
- LLM Backbone:LLM 主干网络,是核心能力载体,一个经过预训练的大语言模型,经过后训练和微调等步骤后可以能够处理多模态的相关 token 和特征输入
- Output Projector:将 LLM 生成投射到 Modality Generator 的特征空间,和 Input Projector 对应
- Modality Generator:多模态生成器,生成各种图像等,例如图片领域的 Stable Diffusion
在多模态领域一般也分成两类别:多模态理解、多模态生成:
- 多模态理解:一般以前三个模块为主,输出形式是文本
- 多模态生成:包含所有的模块,通常来说会更加的复杂
Qwen-VL
Qwen-VL 出现的时间点在于 BLIP2 以及 LLaVA 之后
简介
文章定义了 LVLM(Large Vision-Language Models)并指出当时开源模型能力远远落后于闭源模型主要缺陷:
- 训练与优化不充分
- 精细看图能力不足:停留在粗略图像理解,定位、OCR 等能力不足
至于解决的方式也很直观明了,为了让 模型具有多维度的能力,而不只是生成一个图像的描述,Qwen-VL 在训练的时候加入了包括 OCR, caption, VQA 等能力全部都加入了进去
架构
Qwen-VL 包含了上文中的前三个典型框架:
- 模态编码器(Modality Encoder) : 视觉编码器(visual encoder),只用来编码图片视觉特征
- 输入投影层(Input Projector):位置感知的适配器(position-aware adapter)
- LLM主干网络(LLM Backbone): Qwen-7B Base 模型
Visual Encoder
视觉编码器使用 ViT 架构,使用的就如同论文中的 14 patch 一样,训练方法是使用 CLIP 对比学习
具体的相关内容可以看 ViT&CLIP 笔记
Input Projector
Qwen-VL 称之为 Position-aware Vision-Language Adapter,位置感知的视觉语言适配器。
字面意思,就是把图像信息适配到语言模型那边,再加上了一个位置感知模块,模块输入的图像大小是 $448 \times 448$ 的图像,输出一个 [1024, 1664] 的维度的序列。
Adapter 中使用一组可学习 query 向量去 cross-attention 图像特征(有点类似 BLIP2 的 Q-former,但是小很多),把视觉序列压缩到 256 的长度,同时在 ca 中加入了 2D 的绝对位置编码(因为大小是固定的)
最后把这 256 个 压缩后的视觉 token 输入给大模型
注意到这里的 qeury 提取实际上和 Q-former 目标不一样,一开始 Qwen 为了提取空间信息的同时压缩信息,加入了 2D 的位置编码,但是 BLIP2 则更偏从 image encoder 中抽出适合 llm 的视觉表示
输入输出设计
这一点值得考究一下,因为这也是Qwen-VL 能够做 OCR 和 图像检测等信息的关键
在图像输入中,使用了两组特殊的 token <img>, </img>来包裹了图像输出的特定长度序列,让 llm 能够理解哪些 token 是图像内容
另外针对于坐标框的输入,将 bbox 归一化到 $[0, 1000)$ 并编码成文本,再使用额外的 token <box>, </box>包裹(1, 5), (500, 501) 这种坐标
同样地,对于描述信息也用 <ref>, </ref>包裹
这样的好处是把图像上的信息转成了一个面向语言任务
训练
训练的大致流程如下,分为三个阶段
Pretrain
冻结LLM,对 Adapter 和 Visual Encoder 执行训练,目标就是让这两个模块可以正常工作,把图像翻译成LLM 能够看得懂的语言表示数据
回忆一下 LLaVA 中的 Pre-training for Feature Alignment 模块,将 Vision Encoder 和 LLM 全都冻结,只训练 Projector,这里略有不同,但是思路都是为了对齐视觉和文本
Multi-task Pre-training
用于补齐细粒度能力,是最重要的模型训练步骤
作者引入了 7 类任务,去训练整个模型的所有模块,这其中就涉及到了 OCR
所以 Qwen-VL 之所以能够完成 Grounding 和 OCR 这些任务,实际上是有显式的任务训练
Supervised Fine-tuning
指令微调,把模型变成能够说人话的,跟随指令的一个模型
这一部分冻结了视觉编码器,重点优化 LLM + Adapter,引入了多模态的 Instruction Tuning(就是 LLaVA 的主要内容)
额外还构造了多图对话,以及一些纯文本的对话,避免多模态失去普通的文本对话能力
总结
总体来看其实 Qwen-VL 没有特别的大创新,总的来说就是引入了额外任务来执行训练,训练流程和 LLaVA 的流程大体上是一致的
Qwen2-VL
相较于 Qwen-VL, Qwen2-VL整体有了较大的更新,让模型能够以一个更加自然的方式理解视觉内容
简介
相关背景简要略过,作者指出的两个问题:
- 模型被分辨率束缚,固定缩放到特定分辨率,对文字本身会丢失很多的细节
- 模型对时间空间的位置建模仍然相对粗糙,图像空间信息是 2D 的,视频更是 3D 的,如何去处理这些模态的位置结构
- 长视频,帧序列的计算成本会非常大,token 上涨非常的快
对此主要提出了两大 insight:
- 图像应当动态的分配视觉 token,而不是固定预算
- 多模态的位置编码应该区分 时间 和 行列 的两个部分,对于不同的模态,分别使用 1D(文本),2D(图像),3D(视频)
- 视频图像应该统一建模,而不是完全割裂的两类模态,可以共享能力
架构
Qwen2-VL 系列发布了多个不同参数量的模型,但是这里的参数主要指的是 llm 的参数量,对于 Vision Encoder 还是一样的,都是 675 M,前端的计算负担相对稳定
另外 Input Projector 使用的是普通的线性层,做了相应的简化策略

Native Dynamic Resolution
全文章最重要的方法之一,让模型可以自适应控制图像的 token 数量,用来应对各种大小的输入图像
原生的 ViT 会对输入图像执行强制变形到一个 1:1 的比例,然后输入到图像中,会有变形
实现的方法是移除了 ViT 的绝对位置编码,而是使用 2D-RoPE 编码
额外使用了一个 token 压缩的小技巧,ViT 后接一个 MLP 把 $2 \times 2$ 的 token 压缩到 1 个中,最后首尾再加上起始和终止的 token <vision_start>, <vision_end>
举个例子,$224 \times 224$ 经过 $14$ patch 后得到 $16 \times 16$ ,经过 $2 \times 2$ MLP 压缩后得到 $8 \times 8 + 2 = 66$ 个 token
阅读后面的消融实验部分可以看到,实际上没有一个固定的分辨率可以在所有的任务上做到最好,过高分辨率有可能会能力下降,尤其是 OCR 的相关任务,所以动态分辨率是泛化性极强的一个决策
M-RoPE
Multimodal Rotary Position Embedding,多模态旋转位置编码,另一个重要方法
将位置拆成三个坐标轴,时间,高度,宽度
对于文本,三个分量采用一个 position,等价于 1D 的 RoPE,对于图像中时域 id 保持不变但是分配了 高度和宽度的位置信息,最后视频会依据帧来执行递增
这相当于给模型一个位置信息,对于视频理解,文档分析等能力会提升不少
消融实验表示,位置编码对于视频的理解能力是极大的提升
Unified Image and Video Understanding
统一图像和视频处理方案。
对于视频,每 1 秒取 2 帧,同时引入了深度为 2 的 3D 卷积来处理图像的输入,把视频处理成 3D 的 tube 而不只是 2D 的 patch,可以理解成把 $14 \times 14 \times 2$ 的一个 时空立方体编码成一个视觉 token,在 patch 的基础上额外减少了时间维度的 token
这样做的好处就省 token,在覆盖了视频的同时节约了 token
训练流程
训练流程和 Qwen-VL 保持一致
- 只训练 ViT:使用 image-text pairs 建立基本的图像理解
- 全参数训练:全方位的多模态学习
- 只训练 LLM:学习 Instruction 能力
Qwen2.5-VL
简介
Qwen2.5-VL 进一步强化了以下几个问题:
- 文档解析:不仅仅是 OCR,包括图表分析,坐标,等等文档布局的分析
- 空间定位:能够框出图像中的不同位置的数据等,具体的坐标信息
- 长视频理解:处理非常长的视频数据
- Agent 交互:面对软件截图等ui界面,能够识别并理解下一步需要做什么,完成分析+定位的能力
Qwen2.5-VL 的策略主要改变在,需要保留原生的分辨率等信息,而不是使用归一化后的信息,强化模型的理解能力
为此作者主要提出了以下几个 Insight:
- 保留真实世界的尺度信息:移除旧思路中的归一化思想,将绝对位置等信息保留,让模型自行理解
- 视频理解需要更好的时间对齐方式:把 M-RoPE 和绝对时间的尺度对齐,模型可以通过 Temporal ID来感知时间的信息
- 文档统一理解:将文档中的所有信息全部映射到同一个 html 中,编码所有的信息,对文档架构的理解力比单纯的 OCR 更强
架构
总体而言依旧是传统的 3 段架构:Vision Encoder + Input Projector + LLM
但是做了一些些改进:
- 把 LLM 的纯文字的 RoPE 改造为了 M-RoPE,更加适配多模态
- ViT 重新设计,支持 2D-RoPE,支持 native resolution
- 视觉 token 经过压缩后再给 LLM 而不是直接全部塞进去
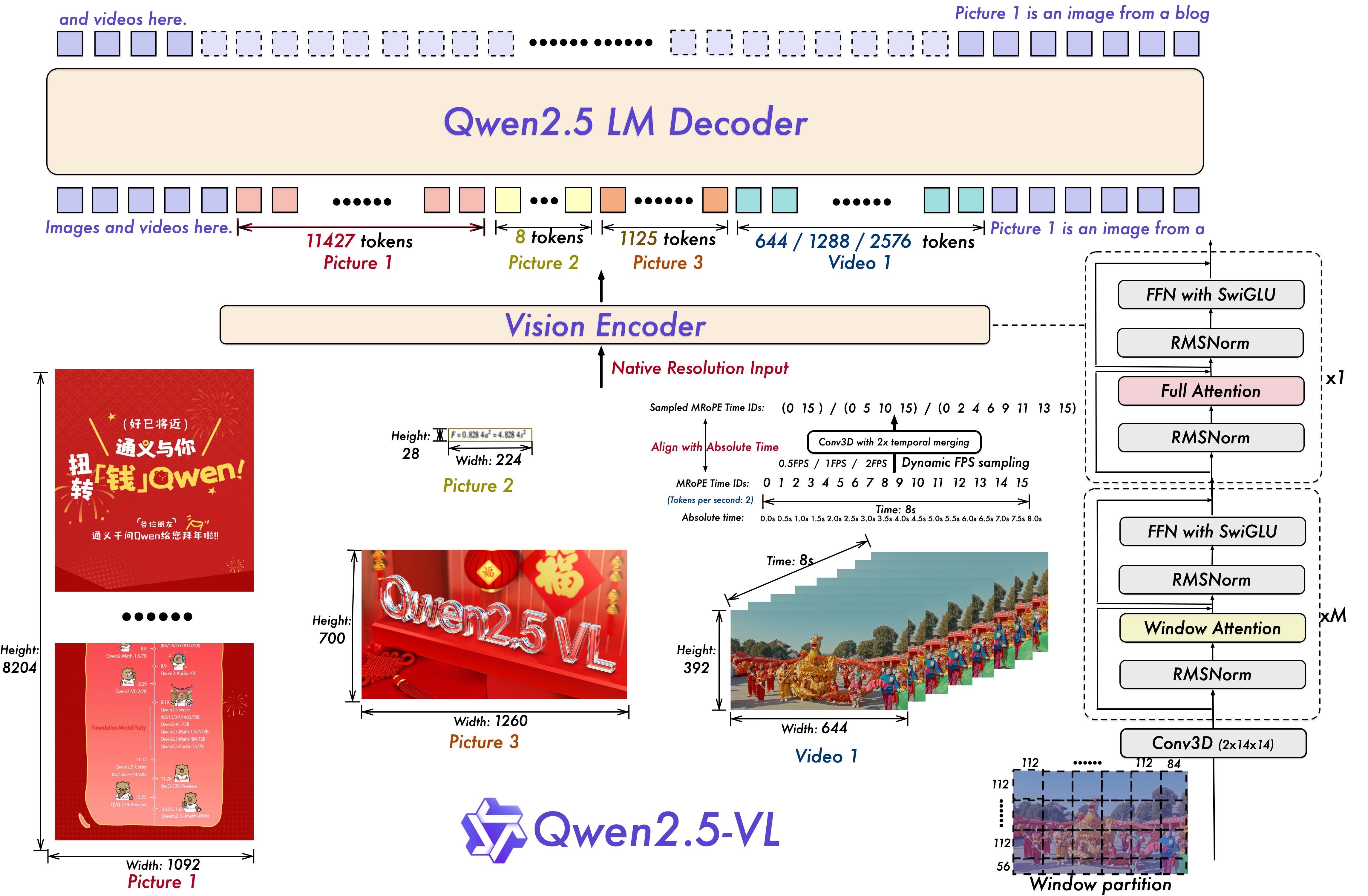
Vision Encoder
基本是最主要的一个改进模块,为了适配多个复杂的任务,重新设计了ViT 模块
引入了 Window Attention1 + 少量的 Full Attention,只有 4 个层使用了 Full Attention 架构,减少了很多的运算量
例如说一个非常长的海报图像,让局部窗口内处理细节信息(例如文字,小图块)已经足够,最后用 4 个 Full Attention 跨区域整合全局信息
对于位置编码,这部分和 Qwen2-VL 保持一致,使用了 M-RoPE 应对视频和图像的信息,对于图像中相邻的两帧被共同处理
ViT 的架构也额外单独设计了一下,以对齐 LLM 的模块,使用了 RMSNorm 以及 SwiGLU,增强了 ViT 模块和 LLM 之间的组合性能。
为什么要使用 RMSNorm 替换 LayerNorm?
对于 $\mu = \frac{1}{d}\sum_{i=1}^d x_i,\quad \sigma^2 = \frac{1}{d}\sum_{i=1}^d (x_i-\mu)^2$ 有 $\text{LayerNorm}(x)_i = \gamma_i \cdot \frac{x_i-\mu}{\sqrt{\sigma^2+\epsilon}} + \beta_i$ ,LN 同时做了两个工作,因此向量的平均值整体偏移,尺度相应缩放
对于 $\mathrm{RMS}(x)=\sqrt{\frac{1}{d}\sum_{i=1}^d x_i^2}$ 有 $\text{RMSNorm}(x)_i = \gamma_i \cdot \frac{x_i}{\mathrm{RMS}(x)+\epsilon}$ 可以发现 RMSNorm 没有减去均值,只控制了尺度
实际上现在的 大部分的 LLM 都在使用 RMSNorm,这里 Qwen-VL 的更换也是同样的原因:
- LN 的计算复杂度高(均值+方差+均值+标准化),RMSNorm 相对算的快(平方和+开根号+缩放)
- LN 数值容易溢出,稳定性相对差一些(LN 减去均值那一步容易在 FP16 发生 catastrophic cancellation)
- 更加接近于 LLM 的主流做法
为什么要把 MLP 换成 SwiGLU?
这还是一个通用问题,现代的 LLM 大多也已经更换了 SwiGLU 来作为前馈网络,不再赘述
Native Dynamic Resolution and Frame Rate
Unlike traditional approaches that normalize coordinates, our model directly uses the actual dimensions of the input image to represent bounding boxes, points, and other spatial features.
分辨率方面:不同于 Qwen2-VL 中执行归一化,这一代的空间维度使用了绝对位置坐标信息,对于不同的 grounding 信息直接使用真实的尺寸表达
帧率方面:将 MRoPE 和 时间戳直接对齐,而不引入额外的时间计算模块
值得注意的是:在 Qwen2-VL 中时间信息的编码是按照帧来计算的,也就是没有考虑原视频的帧率(对于一个 30 FPS 和 60 FPS的视频两帧,现实时间间隔是不一样的),因此这里做了个改动,和现实的绝对时间对齐。
具体的改动可以看 Transformers 中的代码
训练
预训练文档数据
文章中额外特意讲了一下 Pretrain 的数据构造,这里就单独讲一下文档的数据构造,这是 Qwen-2.5-VL 提升文本理解力相对重要的一个地方
在数据中将各种元素全部都放进一个带有 bbox 的 html 文件,例如这样子
<html><body>
# paragraph
<p data-bbox="x1 y1 x2 y2"> content </p>
# table
<style>table{id} style</style><table data-bbox="x1 y1 x2 y2" class="table{id}"> table content
</table>
# chart
<div class="chart" data-bbox="x1 y1 x2 y2"> <img data-bbox="x1 y1 x2 y2" /><table> chart content
</table></div>为了是让一个统一的模型在一个统一的表示中同时理解这些元素,因此模型学到的不仅仅是元素的识别能力,更是阅读顺序,文档结构这些空间上的能力
流程
最大的改进就是 训练的数据集大了很多,从 Qwen2-VL 的 1.2T 扩大到了 4T,总体的预训练结构没有发生大变化
- 只训练 ViT,包括 caption, OCR 等
- 全部解冻训练,加入 Agent,VQA 等理解性的工作
- Long-Context,强化模型的长序列理解能力,加入更长的训练数据
后面还有两个后训练,都把 ViT 冻结了,只调整 LLM,让模型“说人话”
- SFT:把模型从训练数据中的输出方式优化到更加适配于下游任务中,也就是指令微调
- DPO:面向人类的偏好蒸馏,让模型的回答更加符合人类的偏好
Qwen3-VL
简介
这篇文章强调了 多模态模型在 文本能力上的支持,也就是要求 VLM 本身的 LLM 长文本性能要得以保留,也就是:
如何构建一个既保留强文本能力、又真正具备长上下文、多图像、视频、文档、OCR、空间推理和 agent 能力的统一 VLM?
作者指出了这些问题:
- 多模态增强,容易伤害纯文本能力,想让模型更强地理解视觉,就要引入大量视觉训练;但视觉训练过强,又可能破坏语言模型原本的文本能力。
- 长文本/ 视频理解能力还是很困难:回顾一下 Qwen2.5-VL,使用的 MRoPE 把 embedding 维度切成 temporal / horizontal / vertical 三块,这会造成频谱分布不平衡,从而影响长视频理解
- ViT 模型中低层保留边缘信息,高层抽取抽象化语义,但是只拿最后一层输出当做特征给 LLM,对于 OCR、图表理解、文档解析、细粒度定位这类任务效果不佳
- 指出频时间信息不该只靠位置编码表达,长视频时 absolute-time position id 会变得很大而稀疏;
- 做一个 多模态的综合模型,需要非常多的任务以及能力组合,这对训练又有新的综合性要求
我们可以显然看到一个发展趋势,就是 VLM 逐渐往多元能力考虑,而不是作为一个单一的图像理解模块,逐渐需要能够承担决策能力,以及很高的指令能力,走向一个全能型的 LLM 架构
在我写下这篇笔记的时候 Qwen 百炼推荐的支持图像的模型不是 Qwen-VL 系列,而是 Qwen Plus。感觉后续可能不会特意强化某个图像模态的特化模型了,而是逐渐强化综合能力,因为图像理解力达到一定程度上后,指令等 LLM 的基模能力成为能力的主要导向了
架构

总体而言依旧是 三模块架构:Vision Encoder, Input Projector (MLP-based Vision-Language Merger), Large Language Model
主要是更新了:
- LLM 使用 Qwen3 Backbone
- Vision Encoder 使用 SigLIP-2
- Deepstack 机制,就是图像上的那个,Vision Encoder 注入到 LLM 部分
Interleaved MRoPE
在Qwen2-VL 的时候就引入了 MRoPE 来对temporal (t), horizontal (h), vertical (w) 三个空间执行编码,这会引入一个频谱上的问题,在长视频序列上会导致效果下降
对此,Qwen3-VL 把他改成了 Interleaved 的形式,让 thw 三个成分交错地分布在整个 embedding 维度上,让每一个时间/空间轴可以覆盖高频和低频的部分,稳定表达长时空信息
传统的 RoPE 是位置编码到 Attention 的 QK 里面,RoPE 通过一组几何级数频率,对不同维度对施加旋转;这些频率天然覆盖了从高频到低频的一整个谱。高频更偏向细粒度、局部位置差异,低频更偏向长距离、全局位置关系。
文本是只有一个轴的,但是 图像和视频有个多个轴,之前的 MRoPE 是吧 embedding 的维度切分成 3 段分给时间高度宽度,这就导致了每一个位置的轴都拿不到完整的频谱,因为 RoPE 的频率是沿着 embedding 的维度排布的。
Interleaved MRoPE 的做法也很简单,就是轮流分开,交错排列实现,在交错以后,每一个轴都可以接触到从高频到低频的整套频率
DeepStack
回望之前的 Qwen-VL 系列都是将 Vision Encoder 的最后一个输出,经过 Projector 翻译成 LLM 听得懂的 token,输入进去的。
Qwen3-VL 引入了 DeepStack 机制,从 vision encoder 的三个不同层抽取视觉特征,通过专门的 merger 投影成 visual tokens,然后分别加到 LLM 前三层的 hidden states 上。
也就是说不是单独的一次给 LLM 视觉信息,而是在 LLM 的前几层连续补齐视觉信息,因为 Vision Encoder 的不同层次也会提取到不同细粒度的信息:
- 浅层:字符形状、边框、线条
- 中层:图表局部结构、文档版式
- 高层:语义概念、物体关系
所以将浅层和中层的信息额外注入 LLM 会提升 OCR 这类较为细的任务的表现(后面的消融实验表明其在 InfoVQA、DocVQA 这类细粒度视觉任务上收益明显)
Video Timestamp
使用显示时间戳而不是单纯使用 position id 来标记时间信息,例如 <3.0 seconds>
回忆一下 Qwen2.5-VL 相对于 Qwen2-VL 的一大提升就是 MRoPE 对帧率执行了特化,也就是让 MRoPE 可以感知到实际视频的现实时间戳,而不是只按照帧数来写。
Qwen3-VL 不再使用这个技术,而是直接显式写入文本时间戳(我觉得这其实有点依赖于 LLM 能力的提升),这样的好处就是:
- 训练数据不需要再考虑覆盖各种 FPS 的数据了,工作量下降了
- 在长时间视频中,position id 会很大很稀疏,现在不会有这个问题了
代价是:增加了 context length,作者认为 tradeoff 是值得的
训练
PreTrain
- 只训练 Merger:也就是那个 DeepStack 的模块,对齐 Vision Encoder 和 LLM (为什么训练 ViT 呢?我估计是用了 Qwen2.5-VL 的架构,直接用对应的模块了)
- 全参数训练:所有模块加入训练,训练数据混合文本单模态和多模态数据(为了保留住单文本能力)
- 长上下文训练:将 Sequence Length 增强到 32K 增加 Video 长度和 Agent 相关的指令训练数据,实际上是为了下文的真正长上下文做好准备,是下一个阶段的 pretrain
- 超长上下文:进一步拉长上下文到 256K,覆盖长视频和长文档的理解
这么这么多的训练数据,实际上数据集的压力非常大的,文章花了很多篇幅讲了数据集处理,但是我笔记中略过了。
PostTrain
- SFT (thinking + non-thinking):non-thinking指的是普通指令跟随,thinking是显式 CoT 推理,并且同样是从 32K 的长度延长到 256K (可以发现这一代蛮注重上下文长度的延长的),另外就是 加入了很多纯文本的训练数据,也是为了强化 Instruction Tuning 的能力
- Strong-to-Weak Distillation:使用 text only 的数据来微调 LLM 模块,可以提升多模态的推理能力。这个步骤就印证了前面说的,多模态想要做好任务,不仅仅是图像理解,LLM部分需要有强推理能力。
- RL (Reasoning) 使用 SAPO 来强化学习coding,数学等能力
- RL (General) 针对于 Agent 模式的强化学习,就是 Thinking + Act + Analyse Feedback + Answer 的流程,分两个阶段,第二个更加复杂
所以说 Qwen3-VL 是有 thinking 模型的,因为在训练的过程中相应训练过,insturct 和 thinking 区分方式就是 postrain 方案不同
- Window Attention:指的是将原始的序列按照 window 切分成 M 个,window 之间不执行 attention,因此整个运算复杂度从 $O(N^2)$ 下降到了 $O(MN)$ ↩